Part 2: Python Ecosystem for EO
Core Python Libraries Overview¶
Python has become the lingua franca of EO processing through powerful libraries. Before diving into the details, let’s revisit data cubes and how we can represent them in Python. EO data cubes in Python are typically represented as labeled multidimensional arrays that integrate data values, coordinates, and metadata. Consider, for example, a 6x7 raster with 4 spectral bands collected over 3 time points. This structured representation allows efficient and intuitive access to complex EO datasets.
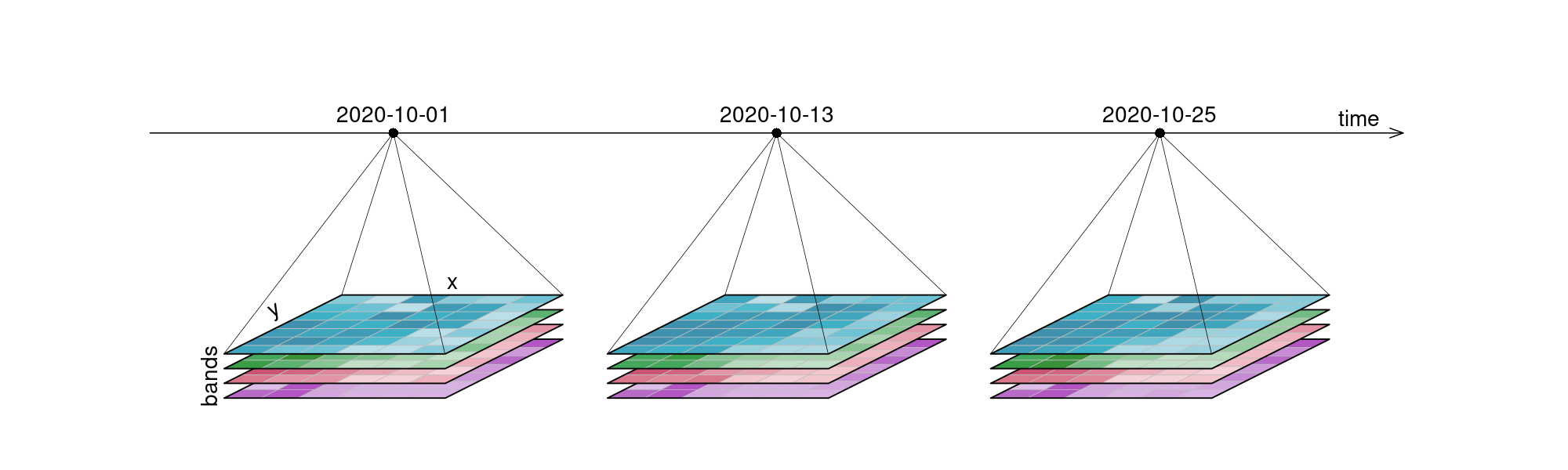
Figure 1:An examplary raster datacube with 4 dimensions: x, y, bands and time.
The demo below uses the Pangeo ecosystem to access and process data.
The list of Python packages below is not exhaustive. Its purpose is mainly to draw a visual picture of the different components typically needed for Earth Observation workflows.
Data Models¶
- xarray → N-dimensional arrays (gridded data).
- geopandas → Tabular vector data (points, lines, polygons).
- shapely → Geometries & spatial operations.
- pyproj → Coordinate systems & reprojection.
- eopf-xarray → Extends xarray with EO Processing Framework methods.
Storage Solutions (I/O & Formats)¶
- rioxarray → GeoTIFFs + CRS handling.
- rasterio → Raster I/O.
- fiona → Vector I/O (GeoJSON, Shapefile).
- Zarr / NetCDF (via xarray) → Cloud-native, chunked array storage.
Catalogs & Metadata (optional)¶
Catalogs are not strictly required — you can load files directly — but they become invaluable when dealing with large, multi-sensor, or cloud-hosted EO datasets.
- pystac → STAC objects (Items, Collections, Catalogs).
- sat-search → Search STAC APIs.
- stackstac → Turn STAC items into xarray stacks.
- odc-stac → Load STAC into xarray (optimized for EO).
Scalable Compute¶
- dask → Parallel/distributed computing.
- pangeo stack → Dask + xarray ecosystem for scalable EO.
User Interfaces & Visualization¶
- hvplot → High-level, interactive plotting (works with xarray, geopandas, dask).
- holoviews / panel → Dashboards and advanced UIs.
- folium / ipyleaflet → Interactive maps in notebooks.
- cartopy → Map projections & static plots.
Resource Management & Deployment (optional)¶
- Kubernetes / Dask Gateway → Manage compute clusters.
- Pangeo Hub / JupyterHub → Multi-user access to scalable EO environments.
Data cubes and Lazy data loading with Xarray¶
When accessing data through an API or cloud service, data is often lazily loaded. This means that initially only the metadata is retrieved, allowing us to understand the data’s dimensions, spatial and temporal extents, available spectral bands, and additional context without downloading the entire dataset.
Xarray supports this approach effectively, providing a powerful interface to open, explore, and manipulate large EO data cubes efficiently.
Let’s open an example dataset to explore these capabilities.
import xarray as xrxr.set_options(display_expand_attrs=False)<xarray.core.options.set_options at 0x1083ddb90>path = (
"https://objects.eodc.eu/e05ab01a9d56408d82ac32d69a5aae2a:202505-s02msil2a/18/products"
"/cpm_v256/S2B_MSIL2A_20250518T112119_N0511_R037_T29RLL_20250518T140519.zarr"
)
ds = xr.open_datatree(path, engine="eopf-zarr", op_mode="native", chunks={})
dsWhat is xarray?¶
Xarray introduces labels in the form of dimensions, coordinates and attributes on top of raw NumPy-like multi-dimensional arrays, which allows for a more intuitive, more concise, and less error-prone developer experience.
How is xarray structured?¶
Xarray has two core data structures, which build upon and extend the core strengths of NumPy and Pandas libraries. Both data structures are fundamentally N-dimensional:
- DataTree is a tree-like hierarchical collection of xarray objects;
- DataArray is the implementation of a labeled, N-dimensional array. It is an N-D generalization of a Pandas.Series. The name DataArray itself is borrowed from Fernando Perez’s datarray project, which prototyped a similar data structure.
- Dataset is a multi-dimensional, in-memory array database. It is a dict-like container of DataArray objects aligned along any number of shared dimensions, and serves a similar purpose in xarray as the pandas.DataFrame.
Accessing Coordinates and Data Variables¶
DataArray, within Datasets, can be accessed through:
- the dot notation like
Dataset.NameofVariable - or using square brackets, like Dataset[‘NameofVariable’] (NameofVariable needs to be a string so use quotes or double quotes)
ds["quality/l2a_quicklook/r60m/tci"]ds.quality.l2a_quicklook.r60m.tciAccessing metadata¶
Metadata describes the data itself — offering context, provenance, and characteristics — in a way that can be read by both humans and machines.
ds["quality/l2a_quicklook/r60m/tci"].attrs{'_eopf_attrs': {'coordinates': ['band', 'x', 'y'],
'dimensions': ['band', 'y', 'x']},
'proj:bbox': [300000.0, 2990220.0, 409800.0, 3100020.0],
'proj:epsg': 32629,
'proj:shape': [1830, 1830],
'proj:transform': [60.0, 0.0, 300000.0, 0.0, -60.0, 3100020.0, 0.0, 0.0, 1.0],
'proj:wkt2': 'PROJCS["WGS 84 / UTM zone 29N",GEOGCS["WGS 84",DATUM["WGS_1984",SPHEROID["WGS 84",6378137,298.257223563,AUTHORITY["EPSG","7030"]],AUTHORITY["EPSG","6326"]],PRIMEM["Greenwich",0,AUTHORITY["EPSG","8901"]],UNIT["degree",0.0174532925199433,AUTHORITY["EPSG","9122"]],AUTHORITY["EPSG","4326"]],PROJECTION["Transverse_Mercator"],PARAMETER["latitude_of_origin",0],PARAMETER["central_meridian",-9],PARAMETER["scale_factor",0.9996],PARAMETER["false_easting",500000],PARAMETER["false_northing",0],UNIT["metre",1,AUTHORITY["EPSG","9001"]],AXIS["Easting",EAST],AXIS["Northing",NORTH],AUTHORITY["EPSG","32629"]]'}Quick Visualisation¶
As an example, we plot the quicklook image to view the RGB image.
import matplotlib.colors as mcolors
import matplotlib.pyplot as pltds.quality.l2a_quicklook.r60m.tci.plot.imshow(rgb="band")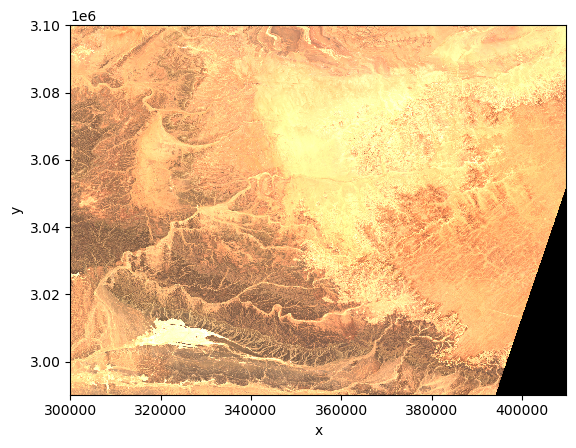
Selection methods¶
As underneath DataArrays are Numpy Array objects (that implement the standard Python x[obj] (x: array, obj: int,slice) syntax). Their data can be accessed through the same approach of numpy indexing.
ds["quality/l2a_quicklook/r60m/tci"][0,0,0]or slicing
ds["quality/l2a_quicklook/r60m/tci"][0,10:110,35:150]As it is not easy to remember the order of dimensions, Xarray really helps by making it possible to select the position using names:
- .isel -> selection based on positional index
- .sel -> selection based on coordinate values
We first check the number of elements in each coordinate of the Data Variable using the built-in method sizes. Same result can be achieved querying each coordinate using the Python built-in function len.
print(ds["quality/l2a_quicklook/r60m/tci"].sizes)Frozen({'band': 3, 'y': 1830, 'x': 1830})
ds["quality/l2a_quicklook/r60m/tci"].isel(band=0, y=100, x=10)Or a slice
ds["quality/l2a_quicklook/r60m/tci"].isel(band=0, y=slice(10,100), x=slice(10,100))The most common way to select an area (here 54x70 points) is through the labeled coordinate using the .sel method.
ds["quality/l2a_quicklook/r60m/tci"].sel(band=1, y=slice(3097890,3094710), x=slice(301830,305970))Visualize on a map with a projection¶
# Assign the CRS (UTM zone 32N)
# Select your DataArray slice
da = ds["quality/l2a_quicklook/r60m/tci"].sel(
band=1,
# y=slice(3097890, 3094710),
# x=slice(301830, 305970)
)
# Assign the CRS (UTM zone 32N)
da = da.rio.write_crs("EPSG:32632")# Reproject to EPSG:4326 (PlateCarree)
da_ll = da.rio.reproject("EPSG:4326")Plot using matplotlib and cartopy¶
import matplotlib.pyplot as plt
import cartopy.crs as ccrs
fig = plt.figure(figsize=[12, 10])
ax = plt.subplot(1, 1, 1, projection=ccrs.Mercator())
ax.coastlines(resolution='10m')
da_ll.plot(
ax=ax,
transform=ccrs.PlateCarree(),
)
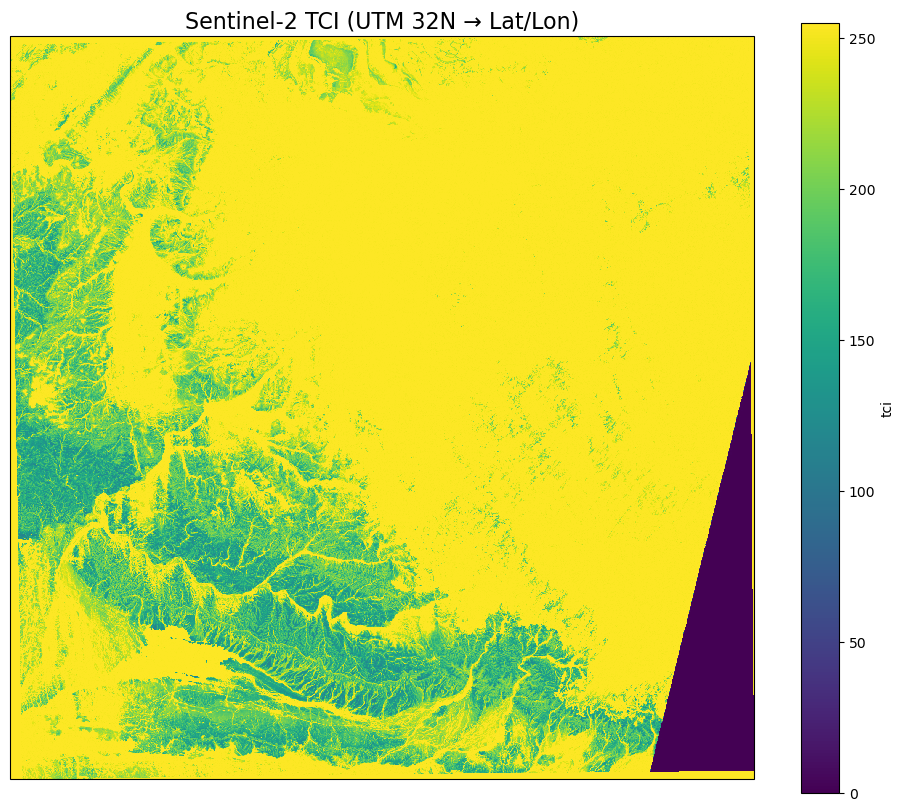
plt.title("Sentinel-2 TCI (UTM 32N → Lat/Lon)", fontsize=16)
plt.show()
But what if I don’t know the file?¶
Earth Observation (EO) data is massive — petabytes across satellites, sensors, and time ranges.
Manually finding files? Difficult. Painful.
We need a way to search and organize EO datasets by space, time, and metadata. In short, we need a catalog.
In EO, the de-facto standard for dataset catalogs is STAC.
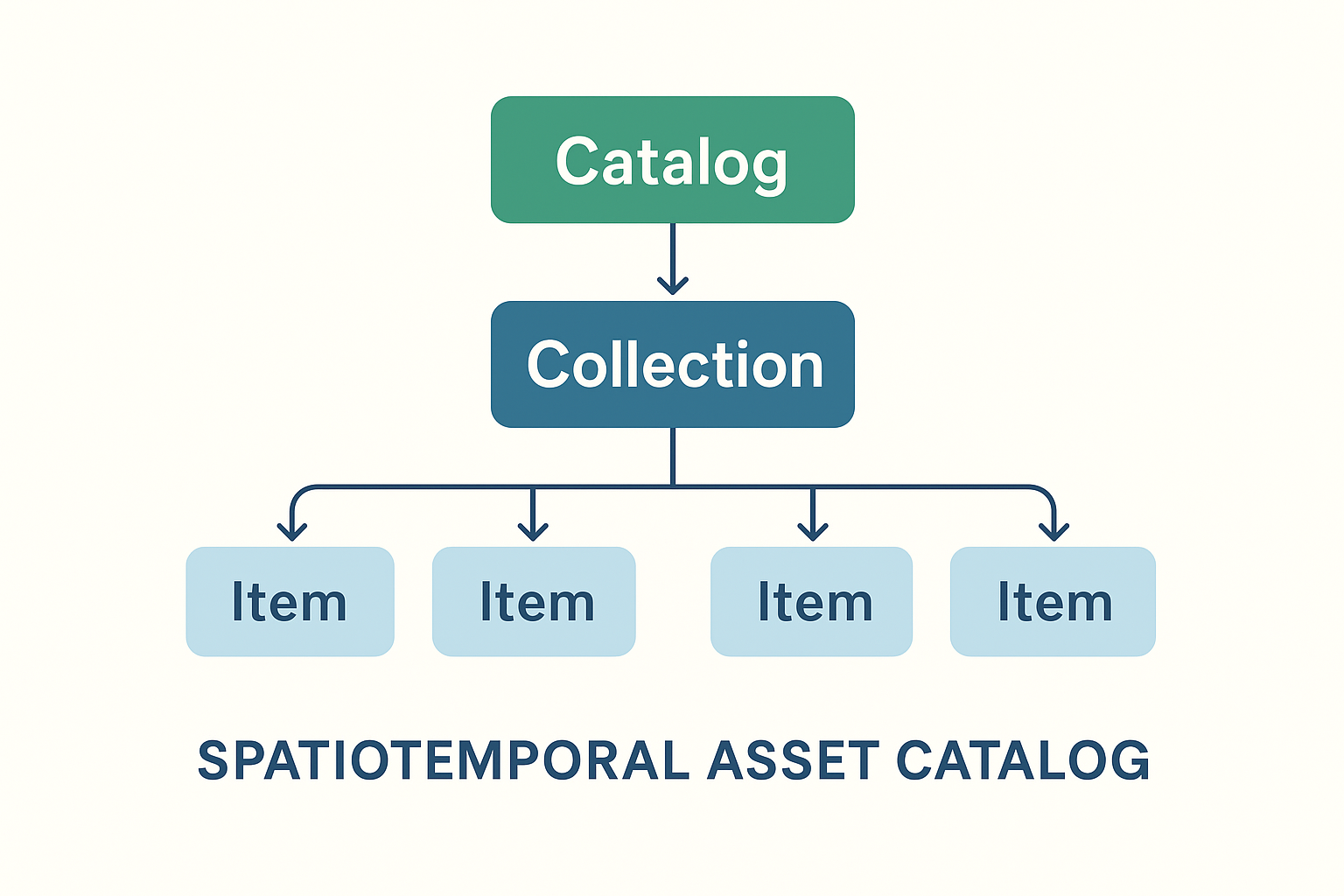
STAC stands for SpatioTemporal Asset Catalog. It’s an open standard, developed by the community, for describing geospatial data — especially large EO datasets like Sentinel, Landsat, or commercial imagery.
Key points:
- Catalog of assets: A STAC is basically a JSON-based catalog that describes geospatial data (satellite images, derived products, etc.).
- Spatiotemporal: Each dataset (called an Item) has metadata about where (bounding box, geometry) and when (timestamp) it was acquired.
- Assets: The actual data files (e.g., GeoTIFFs, Cloud-optimized GeoTIFFs, NetCDF, Zarr) are linked as “assets” in the STAC Item.
- Collections: Items are grouped into collections (e.g., Sentinel-2 L2A).
- Catalogs: Collections can be organized hierarchically, enabling scalable discovery across petabytes of EO data.
Let’s access Sentinel-2 satellite imagery using a STAC (SpatioTemporal Asset Catalog) interface. Leveraging the pystac-client, xarray, and matplotlib libraries, the notebook demonstrates how to:
- Connect to a public EOPF STAC catalog hosted at https://
stac .core .eopf .eodc .eu. - Perform structured searches across Sentinel-2 L2A collections, filtering by spatial extent, date range, cloud cover, and orbit characteristics.
- Retrieve and load data assets directly into xarray for interactive analysis.
- Visualize Sentinel-2 RGB composites along with pixel-level cloud coverage masks.
import matplotlib.colors as mcolors
import matplotlib.pyplot as plt
import numpy as np
import pystac_client
import xarray as xr
from pystac_client import CollectionSearch
from matplotlib.gridspec import GridSpec# Initialize the collection search
search = CollectionSearch(
url="https://stac.core.eopf.eodc.eu/collections", # STAC /collections endpoint
)
# Retrieve all matching collections (as dictionaries)
for collection_dict in search.collections_as_dicts():
print(collection_dict["id"])sentinel-2-l2a
sentinel-3-olci-l2-lfr
sentinel-1-l2-ocn
sentinel-3-slstr-l2-lst
sentinel-1-l1-grd
sentinel-2-l1c
sentinel-1-l1-slc
sentinel-3-slstr-l1-rbt
sentinel-3-olci-l1-efr
sentinel-3-olci-l1-err
sentinel-3-olci-l2-lrr
Sentinel-2 Item Search¶
Querying the Sentinel-2 L2A collection by bounding box, date range, and cloud cover
catalog = pystac_client.Client.open("https://stac.core.eopf.eodc.eu")
# Search with cloud cover filter
items = list(
catalog.search(
collections=["sentinel-2-l2a"],
bbox=[7.2, 44.5, 7.4, 44.7],
datetime=["2025-01-30", "2025-05-01"],
query={"eo:cloud_cover": {"lt": 20}}, # Cloud cover less than 20%
).items()
)
print(items)[<Item id=S2B_MSIL2A_20250430T101559_N0511_R065_T32TLQ_20250430T131328>, <Item id=S2C_MSIL2A_20250425T102041_N0511_R065_T32TLQ_20250425T155812>, <Item id=S2C_MSIL2A_20250418T103041_N0511_R108_T32TLQ_20250418T160655>, <Item id=S2C_MSIL2A_20250405T102041_N0511_R065_T32TLQ_20250405T175414>]
Quicklook Visualization for Sentinel-2¶
We can use the RGB quicklook layer contained in the Sentinel-2 EOPF Zarr product for a visualization of the content:
item = items[0] # extracting the first item
ds = xr.open_dataset(
item.assets["product"].href,
**item.assets["product"].extra_fields["xarray:open_datatree_kwargs"],
) # The engine="eopf-zarr" is already embedded in the STAC metadata
dsds.quality_l2a_quicklook_r60m_tci.plot.imshow(rgb="quality_l2a_quicklook_r60m_band")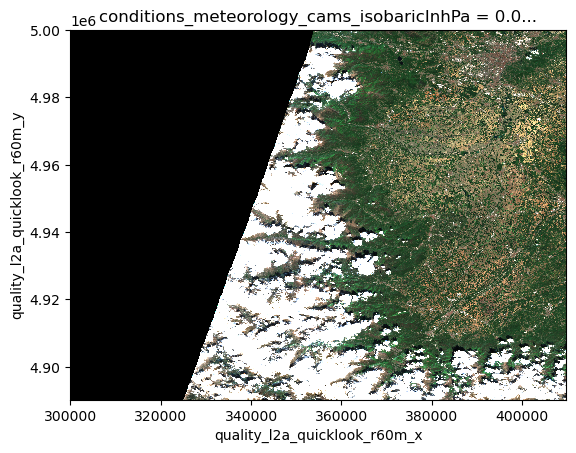
There isn’t just one STAC catalog¶
There are many STAC catalogs, each hosting different collections of datasets. A collection groups related assets, such as all Sentinel-2 images for a region, or all Landsat scenes for a certain period. By browsing catalogs and their collections, users can quickly find the data they need without hunting through petabytes of raw files.
The STAC catalog at https://
import stackstac# West, South, East, North
spatial_extent = [11.1, 46.1, 11.5, 46.5]
temporal_extent = ["2015-01-01","2022-01-01"]Running this cell may take up to 2 minutes
URL = "https://earth-search.aws.element84.com/v1"
catalog = pystac_client.Client.open(URL)
# Search Sentinel-2 L2A items
items = catalog.search(
bbox=spatial_extent,
datetime=temporal_extent,
collections=["sentinel-2-l2a"]
).item_collection()Calling stackstac.stack() method for the items, the data will be lazily loaded and an xArray.DataArray object returned.
Running the next cell will show the selected data content with the dimension names and their extent.
# Stack into a datacube
datacube = stackstac.stack(
items,
bounds_latlon=spatial_extent,
epsg=32632, # UTM zone for tile 32N
resolution=10, # 10m pixels
chunksize=4096 # optional, improves performance
)
datacubeFrom the output of the previous cell you can notice something really interesting: the size of the selected data is more than 3 TB!
But you should have noticed that it was too quick to download this huge amount of data.
This is what lazy loading allows: getting all the information about the data in a quick manner without having to access and download all the available files.
Quiz hint: look carefully at the dimensions of the loaded datacube!
Data Formats and Performance¶
Chunking Explained¶
When working with large Earth Observation datasets, it’s usually not possible to load all data into a computer’s memory at once. Instead, data is divided into smaller, manageable chunks. Each chunk is the smallest unit that can be processed independently. This chunking strategy enables efficient, piecewise data access and parallel processing, improving performance and scalability.
The figure below visually explains the concept of data chunking: on the left, a three-dimensional data cube (x, y, and time) is shown without chunks, while on the right, the same data cube is displayed with chunks highlighted.
| Data Cube without chunking | Data Cube with chunking |
|---|---|
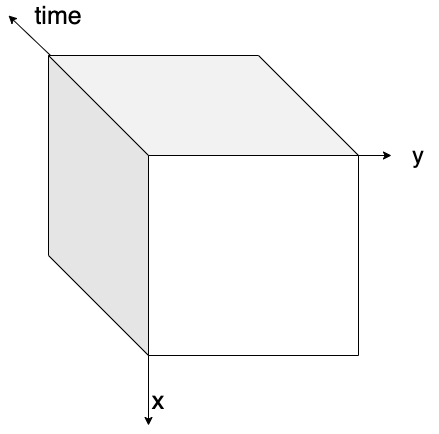 | 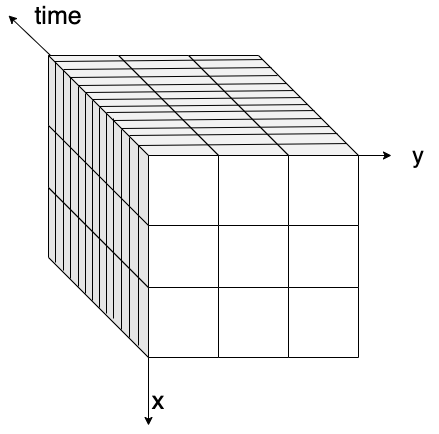 |
Figure: on the left, a 3D data cube without any chunking strategy applied. On the right, a 3D data cube with box chunking.
There are several ways to chunk data depending on the analysis needs:
- Spatial chunking divides data by geographic regions (e.g., longitude and latitude), ideal for spatial queries.
- Time-based chunking divides datasets along temporal dimensions, useful for time series analysis.
- Box chunking partitions data into fixed-size, 3D blocks combining space and time.
Choosing an appropriate chunking strategy is crucial, as it impacts read performance, memory usage, and cost-effectiveness in cloud environments.
Q&A: What Did You Discover?¶
3 minutes
Key Concepts Participants Should Understand:
- Memory Efficiency: Chunking enables processing datasets larger than RAM
- Lazy Evaluation: Build complex operations without immediate computation
- Cloud-Native: Stream only needed data chunks from remote storage
- Scalability: Same patterns work from laptop to supercomputer
Questions for Understanding:
- “How does chunking solve the ‘big data’ problem?”
- “Why is lazy evaluation important for satellite data analysis?”